Kai van Lieshout and Dr. Ray Boyapati made the case at Australia's Digital Health Festival 2026 for what purpose-built clinical AI must look like as the technology moves deeper into care.

This is our fourth year at DHF. In 2023, our first year, we were in the back corner of Startup Alley in basically a one-metre booth. We were the only Clinical AI Tool at DHF, and we spent most of our conversations explaining that AI could, in fact, do the paperwork for you. A few things have changed since then.
AI has quickly moved into bigger and more complex parts of healthcare: decision support, workflow automation, agents. By comparison, an early Clinical AI Tool that just writes the note can sound pretty simple. But looking back, I do not think it ever was. Even a seemingly simple clinical note has a meaningful impact on the way care is delivered. It becomes part of the patient record, the basis for what gets followed up, referred, and actioned. And now these tools are moving further upstream. The downstream impact is exponential.
RAYFrom where I sit in the clinic, AI tools feel categorically different to anything I have seen before in medicine. My EMR stores information. My referral system moves clinical details from A to B. But AI tools generate clinical content in real time, at scale, across different environments. And that content shapes what a clinician sees and how they act.
A patient is discharged from hospital. Two days later they call back, short of breath. The AI system triages it as routine and books a follow-up for next week. But it was not deeply connected to the clinical record. It did not know the patient had surgery. It did not know that surgery puts them at high risk of pulmonary embolus, or that shortness of breath is a cardinal symptom. It did not know because it was never built to know.
"In medicine, when the stakes rise, the standard rises with them. The same has to be true for clinical AI."
Dr. Ray Boyapati, Chief Clinical Officer, Lyrebird Health


Lyrebird started with writing clinical notes. But we quickly realised how connected notes are to everything else: referrals, care plans, billing, and how much that varies by specialty, setting, region, and patient population. Something generic cannot safely support clinical work.
One example that stands out: early on, in some rural settings, Lyrebird was not reliably documenting social history screening for indigenous patients. The doctors told us they screened alcohol intake using a more casual framing. Lyrebird was interpreting this as social chat, rather than an intentional clinical datapoint that is simply screened differently depending on the care setting. We caught this because we had the clinical feedback loops to recognise why it mattered.
RAYA GP managing chronic disease in rural Queensland is completely different to a surgical outpatient clinic in London or a paediatric ED at three in the morning. These are not minor variations. They are completely different clinical environments, with different ways of working, different terminology, different patient populations, and different clinical risks.
The stakes of healthcare are too great for anything less than purpose-built clinical AI
A tool that earns trust in the clinical settings it serves, and keeps earning it as the technology takes on more responsibility.

The future of clinical AI will be defined by those who earn trust in the clinical setting they serve and keep earning it as the technology takes on more responsibility. Purpose-built AI is not something you build once and declare finished. It is something you need to keep earning as the product is used and evolves in the real world.
So we asked: what does that actually mean in practice? We landed on three things. Scale deliberately, so you understand the variation before you claim to serve it. Gather insights from the real world, not just your own internal signals. And define the standard, because someone has to start.
Scaling without intent does not solve the problem. It makes it worse: more contexts you do not understand, more patients where you are getting it wrong without knowing it. The solution is to scale deliberately.
In medicine, we understand this intuitively. A doctor does not specialise on day one. They go broad within their discipline, enough settings and enough patients to build real clinical judgment, then they go deep. The breadth makes the depth possible, but only if it is intentional. That is how we think about building clinical AI.
KAIIn May already, Lyrebird has helped make documentation easier for over a million consultations in Australian general practice. In the NHS, we are rolling out the largest deployment of clinical AI across 20,000 clinicians in the South West London Integrated Care Board. Scale reflects a level of confidence in the product. But it also increases the responsibility, because more clinicians means more contexts, patients, and edge cases.

Scale matters, but only if you use it properly. More use gives you more signals, but it can also make you overconfident. Part of building this responsibly is deliberately looking for where the product falls down, not waiting for problems to find you.
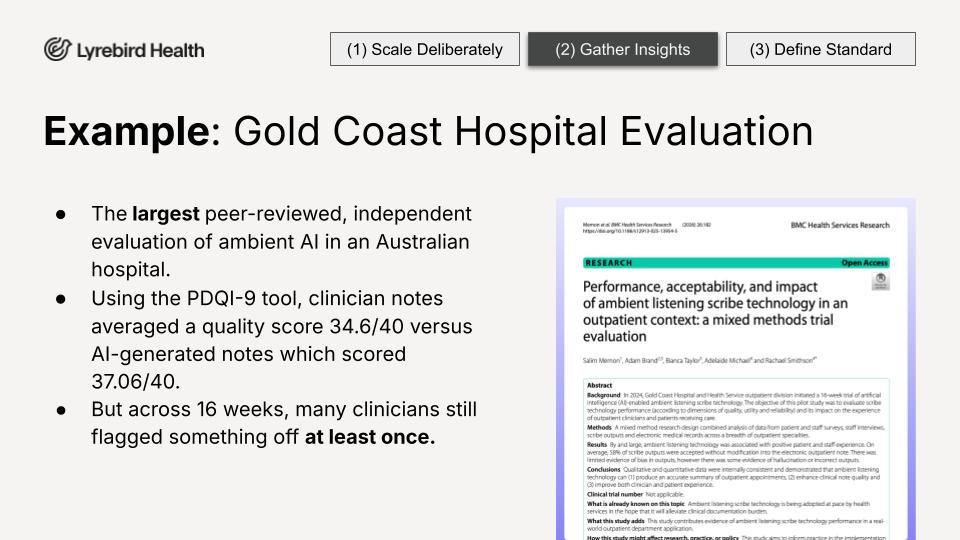
Our deployment at Gold Coast Hospital is the largest deployment of ambient AI in an Australian hospital setting, now with over 1,500 active clinicians. They wanted to run an independent, peer-reviewed evaluation and publish it. We said yes. Not because we knew what the analysis was going to say, but because we wanted it, and deeply believed it should be published either way.
RAYThe findings were really interesting. Strong efficiency gains. Time saving. Patients reporting more direct time with their doctors. And Lyrebird notes scored higher on average on a validated quality instrument. Sounds great. But let us look a little deeper.
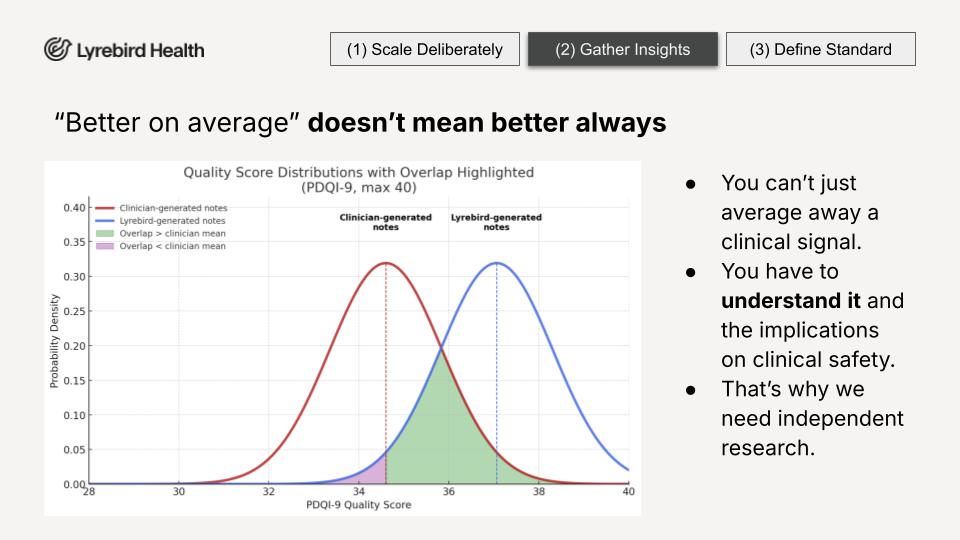
Yes, Lyrebird scored higher on average on the PDQI-9. But not better all the time. And across 16 weeks of real-world evaluation across multiple specialties, a number of clinicians found something that did not quite look right in the note at least once. In medicine, you cannot average away a clinical signal. You have to understand it. That is exactly what independent real-world research is for.
"Most errors are not a model problem. They are a context problem. If you are not close enough to the clinical context, you cannot see the error, let alone fix it."
Dr. Ray Boyapati, Chief Clinical Officer, Lyrebird HealthIn medicine, you do not get to decide the standard on your own. There are guidelines, professional bodies, and peer review. That infrastructure exists because the stakes are so high. In clinical AI, that infrastructure is still being built. But someone has to start, and you can only set a meaningful standard if you have done the work.
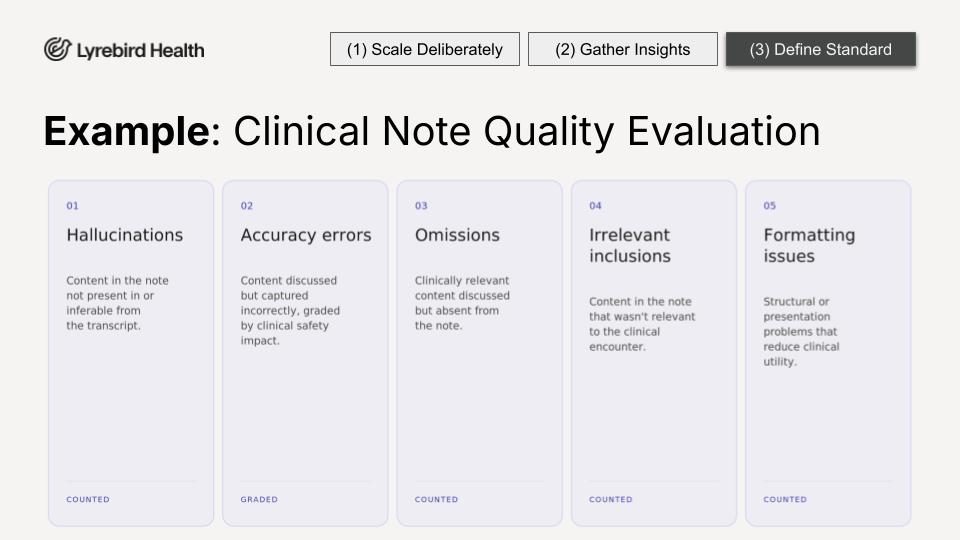
There is no industry standard for this yet, so we built and published our own. The clinical evaluation framework asks clinicians not to rate the note from one to five, but to find specific, discrete, countable errors. Was there a hallucination? Was there an omission? A score of four out of five does not tell you what went wrong. Countable errors give you something you can act on.
"Limited mobility due to knee injury"
The patient mentioned a sore knee and time off work. The phrasing was not said exactly, but most clinicians would find it clinically reasonable. Low risk.
"Patient denies allergies"
The patient reported a penicillin allergy. This is a direct contradiction that could lead to a dangerous prescribing decision. Must be categorised separately.



If clinical AI is going to shape what gets trusted, captured, and acted on, generic is not good enough. It is something a tool has to keep earning through deliberate scale, feedback loops, and intentional systems that surface what is missing. Independent evidence that challenges what we think we know is absolutely essential.
This is not an abstract question about the future. This year in Australia, at least 42 million consultations are going to involve AI. That number is only going in one direction. We need to decide what the standard is now.
RAYFor me, it comes down to this. Next week I will be in clinic, and sitting across from me will be a patient. I need to know, really know, that the AI tool I bring into that room belongs there. If it belongs, it can make me a better doctor, help me connect with my patients, and improve their health outcomes.
But if that tool has been built too fast, too generically, too broadly, then that is a risk to my patient. And that is not a standard I am willing to accept. If you are in this room, you would not accept it either.
KAIIf you are in this room, you are part of this conversation. Come find us and join us. We would love to chat. Let us build this exciting future in clinical AI together, responsibly. Thank you.
Clinical AI is being normalised across 42 million consultations this year in Australia alone. The standard being set today will define what patients experience for years. Build it with us.

